
Nous allons aujourd’hui apprendre à mettre en œuvre un algorithme pour permettre à un réseau de neurones multicouches d’apprendre à classer des données. Nous verrons donc pourquoi il est nécessaire de mettre en place une méthode spécifique pour ce type de réseau de neurones, nous verrons ensuite comment cet apprentissage fonctionne puis nous apprendrons à le mettre en œuvre en construisant trois exemples de réseaux multicouches.
Table des matières :
- L’apprentissage des réseaux multicouches
- Mécanisme d’apprentissage
- Mise en oeuvre d’un algorithme d’apprentissage
- Conclusions
L’apprentissage des réseaux multicouches
Il existe aujourd’hui plusieurs algorithmes basés sur ce que l’on appelle la descente de gradient. Il s’agit de minimiser progressivement l’erreur du réseau de façon itérative en nous appuyant sur le dérivé de la fonction de calcul de l’output. Le but de ces algorithmes étant de parvenir à une valeur optimale des poids des connexions entre les neurones en propageant cette information dans le réseau. On parle alors de rétro-propagation puisqu’il s’agit tout simplement de faire passer l’erreur du réseau depuis la couche d’output jusqu’à la couche d’input. Ce terme fait d’ailleurs écho à la rétro propagation neuronale, qui est un phénomène naturel assez similaire que l’on peut observer dans les neurones biologiques, même s’ il n’y a pas de consensus sur les raisons exactes de ce phénomène.
Pour comprendre son fonctionnement, il est d’abord important de rappeler que les réseaux de neurones multicouches utilisent des fonctions d’activation non binaires dont le but est d’estimer une valeur d’output. Par conséquent, un réseau de neurones multicouches ne calcule pas une valeur définitive mais une estimation (il n’y a pas un mécanisme à seuil comme pour le perceptron, un autre algorithme de machine learning). Une condition essentielle pour mettre en place la rétro-propagation du gradient est l’utilisation de fonctions pour lesquelles il existe un dérivé. Cette condition n’est pas respectée par la fonction Heaviside utilisée par le perceptron par exemple dans la mesure où il n’existe pas de dérivé calculable. Les fonctions d’activation les plus connues sont les fonctions Sigmoïde et Tanh. On utilise également beaucoup RELU aujourd’hui. Voici un exemple de réseau très simple avec trois inputs et un seul neurone intermédiaire :
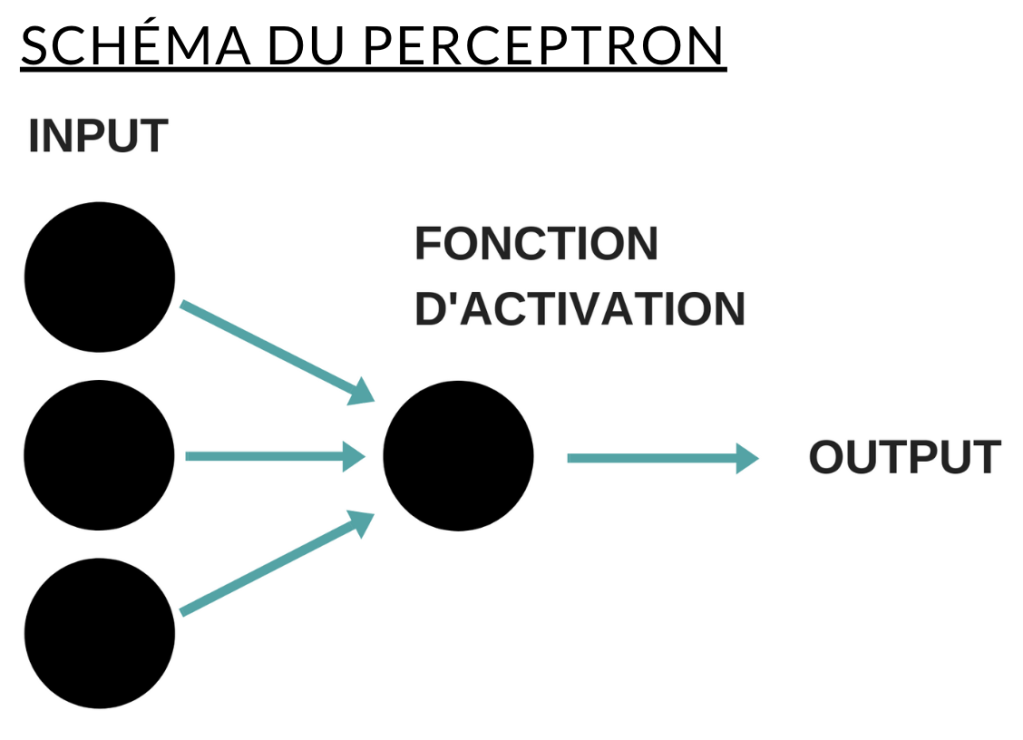
Mécanisme d’apprentissage
La première étape de l’apprentissage d’un tel réseau se nomme la propagation vers l’avant. Il s’agit tout simplement de réaliser la même opération qu’avec un perceptron. Nous multiplions donc la valeur de l’input par la valeur du poids de la connexion avec le nœud intermédiaire (qui est un neurone artificiel). Nous faisons passer cette valeur provisoire dans une fonction d’activation non-binaire (par exemple Sigmoïde). Nous multiplions ensuite ce résultat par la valeur du poids de la connexion avec le nœud d’output (soit le neurone de sortie). Nous faisons également passer cette valeur provisoire par une fonction d’activation non-binaire. Le résultat final nous donne une estimation de l’output calculé par le réseau. La seconde étape, qui est l’étape d’apprentissage, consiste d’abord à calculer l’erreur globale de notre réseau pour pouvoir ensuite propager la correction nécessaire dans l’ensemble des couches. Ce calcul se fait à l’aide de la formule suivante :
Erreur du réseau = Output attendu — Output calculé
C’est la même méthode que celle utilisée pour l’algorithme du perceptron. Il faut ensuite propager cette erreur à l’ensemble des poids du réseau. L’algorithme le plus connu était l’algorithme de la rétro-propagation du gradient. L’idée étant de propager vers l’arrière l’erreur du réseau en tenant notamment compte de l’erreur de chacun des neurones de la couche intermédiaire. Il s’agit en fait d’une généralisation d’un autre algorithme utilisé dans l’apprentissage des neurones simples (ou perceptron). Il s’agit de la règle du delta ou “ Delta Rule “ en anglais. Sa formule est la suivante :
Poids += Erreur du réseau * Dérivé de la fonction d’activation du neurone * Valeur du neurone précédent * Constante d’apprentissage
Comme vous pouvez le constater, nous avons besoin de disposer d’une fonction d’activation dont on puisse calculer le dérivé (ce qui exclut la fonction Heaviside). Cet algorithme s’applique normalement au perceptron, mais on peut assez facilement généraliser la règle décrite. L’idée étant d’appliquer la correction de l’avant vers l’arrière du réseau, on va pouvoir appliquer à chaque fois la correction sur les poids en prenant pour référence le neurone vers lequel ces poids sont dirigés pour utiliser sa valeur provisoire dans le calcul du dérivé de la fonction d’activation. La valeur du neurone précédent correspond à la valeur définitive d’un neurone précédent ou à une valeur d’input. La constante d’apprentissage va servir quant à elle à calibrer la modification pour qu’elle soit aussi progressive que possible. Nous aurons donc d’abord la formule suivante pour le calcul de la mise à jour des poids de la couche d’output :
Poids de la couche d’output += Erreur du réseau * Dérivé de la fonction d’activation du neurone * Valeur du neurone précédent * Constante d’apprentissage
Dans le cas où nous arrivons à l’extrémité du réseau, soit sur les couches d’input et dans le cas où nous avons seulement une seule couche cachée, on peut simplement faire évoluer la formule de la façon suivante :
Poids de la couche cachée += Erreur du réseau * Poids de la couche d’output * Dérivé de la fonction d’activation du neurone * Valeur d’input * Constante d’apprentissage
Nous utilisons la valeur du poids vers l’output car nous avons besoin de proportionner l’erreur des neurones de la couche cachée à la valeur des poids vers la sortie. Cet algorithme va ainsi nous permettre de calculer progressivement une valeur optimale pour l’ensemble des poids en tenant compte de l’erreur globale et des variations locales dans le réseau. Maintenant que nous connaissons le fonctionnement d’un algorithme d’apprentissage, nous allons pouvoir le mettre en œuvre en construisant des réseaux de neurones pour en faire la démonstration pratique.
Mise en oeuvre d’un algorithme d’apprentissage
Pour apprendre à mettre en œuvre un algorithme d’apprentissage, nous allons tout simplement développer trois réseaux de neurones en Javascript. Le code restera très simpliste de façon à faciliter la bonne compréhension des choses. Nous allons pour commencer construire un réseau avec seulement un seul input et un seul neurone intermédiaire. Il s’agit d’un modèle très simpliste, mais cela va nous permettre de mettre en œuvre de façon simple ce que nous avons vu avant. Voici le schéma d’un réseau multicouche moderne pour illustration :
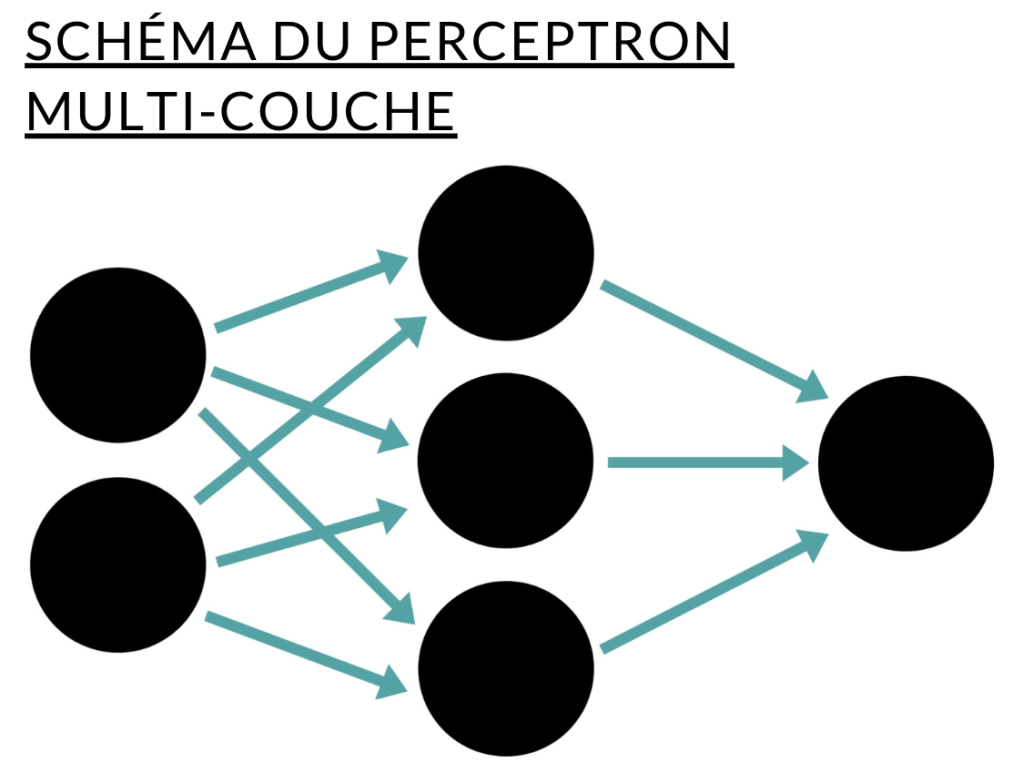
Nous commençons donc d’abord par importer une valeur d’input et d’output en déclarant les variables correspondantes en début de programme :
var Input = 1
var Output = -1
La valeur d’output est ici égale à -1 car nous allons faire appel à une fonction d’activation périodique. Il s’agit de la fonction d’activation “Sin” dont le dérivé est “Cos”. Sa valeur varie entre -1 et 1. Cette fonction d’activation n’est pas très courante dans la mesure où elle peut être difficile à optimiser. Nous l’utiliserons ici à titre d’exemple car elle est facile à calculer. Juste à la suite, nous allons également déclarer les poids des connexions en utilisant les variables “W1” (pour le poids entre l’input et le neurone intermédiaire) et “W2” (pour le poids entre le neurone intermédiaire et l’output). Les valeurs de ces poids sont générées de manière aléatoire :
var W1 = Math.random()
var W2 = Math.random()
Nous pouvons ensuite déclarer les variables correspondants aux neurones. Nous pouvons donc déclarer la variable “N1” (pour le neurone intermédiaire) et “N2” (pour le neurone d’output). La valeur définitive des neurones correspond à la multiplication de l’input et du poids dont le résultat passe ensuite dans une fonction d’activation non-binaire. Il s’agit tout simplement de réaliser l’opération de propagation vers l’avant. Ajoutons le code suivant :
var N1 = Math.sin(Input * W1)
var N2 = Math.sin(N1 * W2)
Nous affichons ensuite les résultats dans la console pour avoir un aperçu de cette propagation vers l’avant :
console.log('Input : { ' + Input + ' } Output : { ' + N2 + ' }')
Si vous lancez le programme maintenant, vous pourrez obtenir un résultat similaire :
Input : { 1 } Output : { 0.1588604470858014 }
Nous venons de faire une propagation vers l’avant. Le résultat que nous obtenons est toutefois assez éloigné de la réalité, puisque nous avons besoin d’obtenir une valeur d’output égale à -1 (ou qui s’en rapproche au maximum si cela est possible). Il est donc impératif de mettre en place une solution pour permettre à notre réseau de converger vers le résultat attendu. Nous allons également mettre en place quelques itérations pour approcher progressivement de cette valeur. Déclarons d’abord la boucle suivante :
for (var i = 0; i < 5; i++) {
Nous déclarons ensuite une variable “TargetCaculated” pour consigner l’écart exact entre l’output attendu et l’output calculé (ce qui correspond à la marge d’erreur globale de notre réseau de neurones) :
var TargetCalculated = Output - N2
Nous pouvons ensuite tout simplement mettre à jour les poids en appliquant les deux formules vues en introduction. Le travail que nous mettons en place correspond maintenant à la propagation vers l’arrière (ou rétro-propagation). Notez bien que le calcul du dérivé de la fonction d’activation des neurones se fait en utilisant les valeurs provisoires de ces derniers. Nous déclarons donc une variable “eW2” pour le calcul de l’erreur sur le poids de la couche de sortie et une variable “eW1” pour le calcul de l’erreur sur le poids de la couche cachée :
var eW2 = TargetCalculated * Math.cos(N1 * W2) * N1
var eW1 = TargetCalculated * W2 * Math.cos(Input * W1) * Input
Nous pouvons ensuite mettre à jour la valeur des poids :
W2 += eW2
W1 += eW1
Maintenant que cela est fait, nous pouvons refaire une propagation vers l’avant et afficher les résultats dans la console ainsi que le nombre d’itérations réalisées :
N1 = Math.sin(Input * W1)
N2 = Math.sin(N1 * W2)
console.log('Iteration number ' + (i+1))
console.log('Input : { ' + Input + ' } Output : { ' + N2 + ' }')
}
Et voici un exemple de résultat :
Input : { 1 } Output : { 0.008347656939536102 }
Iteration number 1
Input : { 1 } Output : { -0.13599879228491732 }
Iteration number 2
Input : { 1 } Output : { -0.7609707996694078 }
Iteration number 3
Input : { 1 } Output : { -0.8524540926433976 }
Iteration number 4
Input : { 1 } Output : { -0.8904546112507578 }
Iteration number 5
Input : { 1 } Output : { -0.9121781670154072 }
Nous avons donc pu faire converger notre réseau vers le résultat attendu. Pour aller plus loin, nous allons maintenant développer un réseau de neurones qui comporte cette fois-ci deux neurones dans la couche intermédiaire mais toujours un seul input.
Comme nous l’avons fait précédemment, nous commençons donc d’abord par déclarer les valeurs d’input et d’output :
var Input = 1
var Output = -1
Nous pouvons ensuite déclarer les variables qui correspondent aux poids des connexions, et générer ces derniers de façon aléatoire :
var W1 = Math.random()
var W2 = Math.random()
var W3 = Math.random()
var W4 = Math.random()
Nous pouvons ensuite déclarer les variables qui correspondent aux différents neurones de notre réseau pour faire une propagation vers l’avant soit “N1” et “N2” pour les neurones intermédiaires et “N3” pour le neurone de calcul de l’output :
var N1 = Math.sin(Input * W1)
var N2 = Math.sin(Input * W2)
var N3 = Math.sin(N1 * W3 + N2 * W4)
Nous pouvons ensuite afficher les résultats dans la console :
console.log('Input : { ' + Input + ' } Output : { ' + N3 + ' }')
Puis nous faisons la même opération que tout à l’heure en réalisant toute une série d’itérations pour obtenir un résultat satisfaisant, en utilisant cette fois-ci une constante d’apprentissage lors de la modification des poids :
for (var i = 0; i < 5; i++) {
var TargetCalculated = Output - N3
var eW4 = TargetCalculated * Math.cos(N1 * W3 + N2 * W4) * N2
var eW3 = TargetCalculated * Math.cos(N1 * W3 + N2 * W4) * N1
var eW2 = TargetCalculated * W4 * Math.cos(Input * W2) * Input
var eW1 = TargetCalculated * W3 * Math.cos(Input * W1) * Input
W4 += eW4 * 0.1
W3 += eW3 * 0.1
W2 += eW2 * 0.1
W1 += eW1 * 0.1
N1 = Math.sin(Input * W1)
N2 = Math.sin(Input * W2)
N3 = Math.sin(N1 * W3 + N2 * W4)
console.log('Iteration number ' + (i + 1))
console.log('Input : { ' + Input + ' } Output : { ' + N3 + ' }')
}
Et voici un exemple de résultat que vous pouvez obtenir :
Input : { 1 } Output : { 0.8313616032702178 }
Iteration number 1
Input : { 1 } Output : { 0.68838468499953 }
Iteration number 2
Input : { 1 } Output : { 0.5227682890054546 }
Iteration number 3
Input : { 1 } Output : { 0.3669015726334703 }
Iteration number 4
Input : { 1 } Output : { 0.23572189829065246 }
Iteration number 5
Input : { 1 } Output : { 0.1277228396383788 }
Vous noterez qu’ici l’amélioration de la valeur d’output est nettement plus progressive que dans le cas précédent avec l’usage d’une constante d’apprentissage. Pour conclure sur ce réseau qui comporte un seul input et deux neurones intermédiaires, nous pouvons décider de classer plusieurs valeurs distinctes qui ne sont pas linéairement séparables. Prenons par exemple l’échantillon suivant :
Input = [[1], [2], [3]]
Output = [[-1], [1], [-1]]
Nous pouvons alors modifier le programme de la façon suivante pour tenter de classer l’ensemble de ces nouvelles valeurs :
var Input = [[1], [2], [3]]
var Output = [[-1], [1], [-1]]
var W1 = Math.random()
var W2 = Math.random()
var W3 = Math.random()
var W4 = Math.random()
var N1
var N2
var N3
function NeuralNet (Input, Output) {
N1 = Math.sin(Input * W1)
N2 = Math.sin(Input * W2)
N3 = Math.sin(N1 * W3 + N2 * W4)
var TargetCalculated = Output - N3
var eW4 = TargetCalculated * Math.cos(N1 * W3 + N2 * W4) * N2
var eW3 = TargetCalculated * Math.cos(N1 * W3 + N2 * W4) * N1
var eW2 = TargetCalculated * W4 * Math.cos(Input * W2) * Input
var eW1 = TargetCalculated * W3 * Math.cos(Input * W1) * Input
W4 += eW4 * 1
W3 += eW3 * 1
W2 += eW2 * 1
W1 += eW1 * 1
}
for (var i = 0; i < 15000; i++) {
for (var j = 0; j < Input.length; j++) {
NeuralNet(Input[j], Output[j])
}
}
for (var j = 0; j < Input.length; j++) {
N1 = Math.sin(Input[j] * W1)
N2 = Math.sin(Input[j] * W2)
N3 = Math.sin(N1 * W3 + N2 * W4)
console.log('Input : { ' + Input[j] + ' } Output : { ' + N3 + ' }')
}
Vous pourrez alors obtenir un résultat assez similaire :
Input : { 1 } Output : { -0.9274124573254745 }
Input : { 2 } Output : { 0.9758190789891488 }
Input : { 3 } Output : { -0.9984094321822803 }
Vous pouvez alors tenter de faire le test avec un jeu de données un peu plus grand, mais vous risquez alors d’obtenir de moins bonnes performances. Exemple de résultats :
// Input = [[1],[2],[3],[4],[5],[6]]
// Output = [[1],[1],[-1],[-1],[1],[1]]
Input : { 1 } Output : { -0.8126367748582578 }
Input : { 2 } Output : { -0.10451135430801568 }
Input : { 3 } Output : { 0.23849170027182495 }
Input : { 4 } Output : { 0.9966007321411149 }
Input : { 5 } Output : { 0.9013036984603294 }
Input : { 6 } Output : { 0.3719902540450187 }
Pour améliorer la qualité des résultats, nous pouvons modifier la valeur de la constante d’apprentissage et également introduire la notion de biais. Il s’agit d’unités supplémentaires qui vont nous permettre de faire converger le réseau. Voici comment ces biais s’intègrent à un tel réseau :
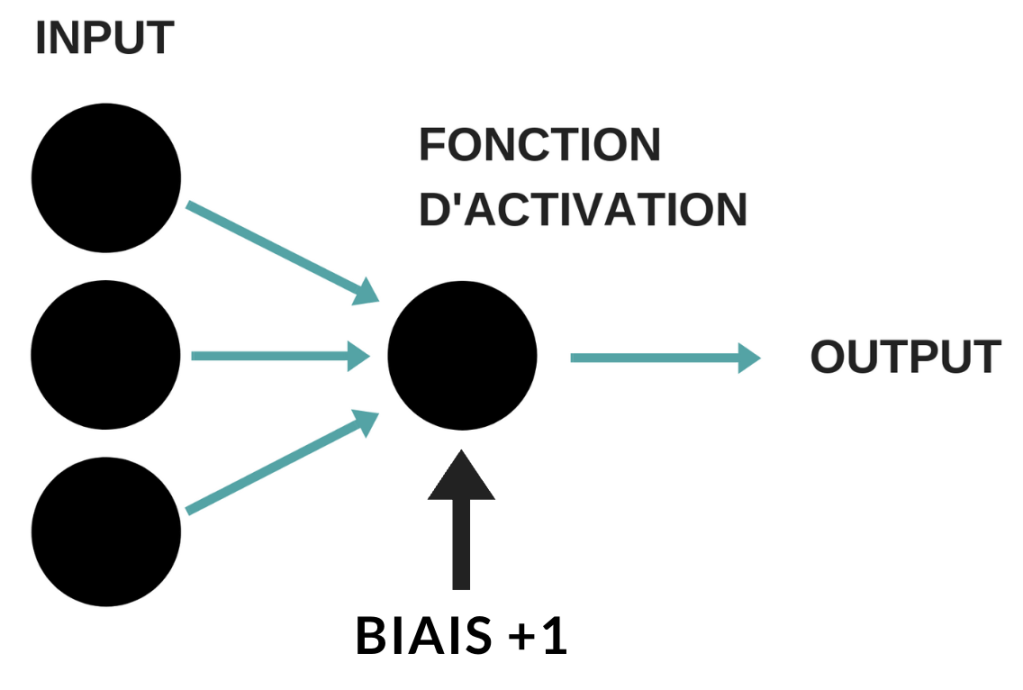
Ces unités supplémentaires sont souvent très utiles pour améliorer l’apprentissage des réseaux de neurones multicouches car elles permettent en quelque sorte de manœuvrer la fonction d’activation et d’ajuster les résultats. Ces biais sont également rattachés à des poids, qui devront être mis à jour tout au long de l’entraînement. Voici donc le code d’un tel réseau où nous intégrons cette fois-ci les biais :
var Input = [[1],[2],[3],[4],[5],[6]]
var Output = [[1],[1],[-1],[-1],[1],[1]]
var W1 = Math.random()
var W2 = Math.random()
var W3 = Math.random()
var W4 = Math.random()
var BW1 = Math.random()
var BW2 = Math.random()
var BW3 = Math.random()
var N1
var N2
var N3
function NeuralNet (Input, Output) {
N1 = Math.sin(Input * W1 + 1 * BW1)
N2 = Math.sin(Input * W2 + 1 * BW2)
N3 = Math.sin(N1 * W3 + N2 * W4 + 1 * BW3)
var TargetCalculated = Output - N3
var eW4 = TargetCalculated * Math.cos(N1 * W3 + N2 * W4 + 1 * BW3) * N2
var eW3 = TargetCalculated * Math.cos(N1 * W3 + N2 * W4 + 1 * BW3) * N1
var eW2 = TargetCalculated * W4 * Math.cos(Input * W2 + 1 * BW2) * Input
var eW1 = TargetCalculated * W3 * Math.cos(Input * W1 + 1 * BW1) * Input
var eBW3 = TargetCalculated * Math.cos(N1 * W3 + N2 * W4 + 1 * BW3) * 1
var eBW2 = TargetCalculated * W4 * Math.cos(Input * W2 + 1 * BW2) * 1
var eBW1 = TargetCalculated * W3 * Math.cos(Input * W1 + 1 * BW1) * 1
W4 += eW4 * 0.01
W3 += eW3 * 0.01
W2 += eW2 * 0.01
W1 += eW1 * 0.01
BW3 += eBW3 * 0.01
BW2 += eBW2 * 0.01
BW1 += eBW1 * 0.01
}
for (var i = 0; i < 20000; i++) {
for (var j = 0; j < Input.length; j++) {
NeuralNet(Input[j], Output[j])
}
}
for (var j = 0; j < Input.length; j++) {
N1 = Math.sin(Input[j] * W1 + 1 * BW1)
N2 = Math.sin(Input[j] * W2 + 1 * BW2)
N3 = Math.sin(N1 * W3 + N2 * W4 + 1 * BW3)
console.log('Input : { ' + Input[j] + ' } Output : { ' + N3 + ' }')
}
Et voici un exemple de résultat :
Input : { 1 } Output : { 0.9618879949533922 }
Input : { 2 } Output : { 0.9582258614268807 }
Input : { 3 } Output : { -0.9877233648057152 }
Input : { 4 } Output : { -0.9867138097917953 }
Input : { 5 } Output : { 0.9603869740928404 }
Input : { 6 } Output : { 0.963174127782338 }
Pour conclure cet article, nous allons maintenant pouvoir faire évoluer le réseau pour résoudre l’équivalent de la fonction XOR en utilisant ce jeu de données qui n’est pas linéairement séparable :
X O
O X
Et voici le code de ce réseau (cette fois-ci, nous n’utilisons pas de constante d’apprentissage) :
var Input = [[1,1], [1,2], [2,1], [2,2]]
var Output = [[-1], [1], [1], [-1]]
var W1 = Math.random()
var W2 = Math.random()
var W3 = Math.random()
var W4 = Math.random()
var W5 = Math.random()
var W6 = Math.random()
var N1
var N2
var N3
function NeuralNet (Input, Output) {
N1 = Math.sin(Input[0] * W1 + Input[1] * W2)
N2 = Math.sin(Input[0] * W3 + Input[1] * W4)
N3 = Math.sin(N1 * W5 + N2 * W6)
var TargetCalculated = Output - N3
var eW6 = TargetCalculated * Math.cos(N1 * W5 + N2 * W6) * N2
var eW5 = TargetCalculated * Math.cos(N1 * W5 + N2 * W6) * N1
var eW4 = TargetCalculated * W6 * Math.cos(Input[0] * W3 + Input[1] * W4) * Input[1]
var eW3 = TargetCalculated * W6 * Math.cos(Input[0] * W3 + Input[1] * W4) * Input[0]
var eW2 = TargetCalculated * W5 * Math.cos(Input[0] * W1 + Input[1] * W2) * Input[1]
var eW1 = TargetCalculated * W5 * Math.cos(Input[0] * W1 + Input[1] * W2) * Input[0]
W6 += eW6
W5 += eW5
W4 += eW4
W3 += eW3
W2 += eW2
W1 += eW1
}
for (var i = 0; i < 15000; i++) {
for (var j = 0; j < Input.length; j++) {
NeuralNet(Input[j], Output[j])
}
}
for (var j = 0; j < Input.length; j++) {
N1 = Math.sin(Input[j][0] * W1 + Input[j][1] * W2)
N2 = Math.sin(Input[j][0] * W3 + Input[j][1] * W4)
N3 = Math.sin(N1 * W5 + N2 * W6)
console.log('Input : { ' + Input[j] + ' } Output : { ' + N3 + ' }')
}
Et voici un exemple de résultat que vous pouvez obtenir :
Input : { 1,1 } Output : { -0.9999687195993059 }
Input : { 1,2 } Output : { 0.999967514901318 }
Input : { 2,1 } Output : { 0.999996077105653 }
Input : { 2,2 } Output : { -0.9999951087401066 }
On peut également adapter notre réseau pour utiliser cette-fois la fonction d’activation Tanh même si celle-ci peut être sensible à une initialisation aléatoire des poids (ce qui implique souvent d’utiliser une méthode spécifique de génération). En effet, les fonctions Tanh et Sigmoïde sont sensibles à ce que l’on appelle la disparition et l’explosion du gradient.
Ces phénomènes causés par une mauvaise initialisation font que le réseau s’arrête d’apprendre ou qu’il devient complètement instable. On peut limiter ce problème en choisissant une méthode d’initialisation spécifique des poids, en utilisant une constante d’apprentissage plus douce ou encore avec des biais. Voici le code nécessaire pour mettre en place un réseau utilisant Tanh comme fonction d’activation :
var Input = [[1,1], [1,2], [2,1], [2,2]]
var Output = [[-1], [1], [1], [-1]]
var W1 = Math.random()
var W2 = Math.random()
var W3 = Math.random()
var W4 = Math.random()
var W5 = Math.random()
var W6 = Math.random()
var N1
var N2
var N3
function NeuralNet (Input, Output) {
N1 = Math.tanh(Input[0] * W1 + Input[1] * W2)
N2 = Math.tanh(Input[0] * W3 + Input[1] * W4)
N3 = Math.tanh(N1 * W5 + N2 * W6)
var TargetCalculated = Output - N3
var eW6 = TargetCalculated * (1-(Math.pow(N3,2))) * N2
var eW5 = TargetCalculated * (1-(Math.pow(N3,2))) * N1
var eW4 = TargetCalculated * W6 *(1-(Math.pow(N2,2))) * Input[1]
var eW3 = TargetCalculated * W6 * (1-(Math.pow(N2,2))) * Input[0]
var eW2 = TargetCalculated * W5 * (1-(Math.pow(N1,2))) * Input[1]
var eW1 = TargetCalculated * W5 * (1-(Math.pow(N1,2))) * Input[0]
W6 += eW6 * 0.01
W5 += eW5 * 0.01
W4 += eW4 * 0.01
W3 += eW3 * 0.01
W2 += eW2 * 0.01
W1 += eW1 * 0.01
}
for (var i = 0; i < 50000; i++) {
for (var j = 0; j < Input.length; j++) {
NeuralNet(Input[j], Output[j])
}
}
for (var j = 0; j < Input.length; j++) {
N1 = Math.tanh(Input[j][0] * W1 + Input[j][1] * W2)
N2 = Math.tanh(Input[j][0] * W3 + Input[j][1] * W4)
N3 = Math.tanh(N1 * W5 + N2 * W6)
console.log('Input : { ' + Input[j] + ' } Output : { ' + N3 + ' }')
}
Et voici un exemple de résultat si l’apprentissage fonctionne :
Input : { 1,1 } Output : { -0.9932471955300527 }
Input : { 1,2 } Output : { 0.9565761922754632 }
Input : { 2,1 } Output : { 0.9274646676066045 }
Input : { 2,2 } Output : { -0.9417442801701745 }
Notre réseau de neurones est donc capable de classifier correctement les valeurs que nous lui soumettons. Toutefois, gardez bien à l’esprit que les cas présentés ici sont très simplistes et que l’algorithme utilisé n’est pas forcément optimal pour des cas réels.
Conclusions
Nous venons donc d’apprendre ici à construire trois réseaux de neurones qui emploient des fonctions d’activation non-binaires et qui disposent d’un mécanisme d’apprentissage leur permettant de propager l’erreur de l’avant vers l’arrière, et de mettre ainsi progressivement à jour les poids des connexions. Les algorithmes basés sur le concept de rétro-propagation du gradient sont essentiels dans le domaine du machine learning, car ils sont indispensables à l’apprentissage des réseaux de neurones multicouches. Ces réseaux sont par ailleurs très utilisés aujourd’hui du fait de leur grande capacité à traiter des jeux de données non linéaires sans avoir besoin d’utiliser plus d’inputs ou de réécrire l’espace de représentation des données. La seule chose à faire étant d’augmenter le nombre de neurones présents ou d’augmenter le nombre de couches. Mais ce point est aussi un inconvénient car il n’existe pas aujourd’hui une méthode unique pour déterminer la meilleure architecture possible pour un réseau. Cela implique une analyse et une compréhension précise du problème à résoudre.

Laisser un commentaire