
Machine learning & traitement de données en JavaScript · Projets utilitaires Python
Ces deux dépôts forment un ensemble complémentaire : le premier, écrit intégralement en JavaScript, couvre un large spectre allant du backend engineering à l’implémentation d’algorithmes de machine learning ; le second, en Python, rassemble des utilitaires ciblés autour du traitement de documents et de la transformation graphique. Tous deux sont distribués sous licence MIT et adoptent la même philosophie architecturale — un répertoire par concept, chaque module fonctionnant de manière autonome.
- 1. Vue d’ensemble
- 2. Répertoire des modules
- 3. Points techniques saillants
- 1. Vue d’ensemble
- 2. Répertoire des modules
- 3. Points techniques saillants
- Synthèse comparative
Partie I
machine-learning-and-data-processing-in-javascript
JavaScript (74,8 %) · HTML (25,2 %) · Node.js + Deno · 484 commits · Licence MIT
1. Vue d’ensemble
Le dépôt est conçu comme un terrain de jeu modulaire : chaque sous-répertoire est un mini-projet autonome illustrant un pattern ou une technique spécifique. Cette structure plate — un répertoire par concept — favorise la découvrabilité et permet à chaque module d’être cloné ou copié indépendamment, ce qui s’aligne avec la vocation pédagogique et de référence de l’ensemble.
Le choix de JavaScript comme langage principal reflète la montée en puissance de Node.js dans les pipelines de data engineering et de machine learning. Le module deno_server signale par ailleurs une veille active sur l’évolution de l’écosystème serveur JavaScript, Deno apportant un support TypeScript natif et un modèle de permissions distinct.
2. Répertoire des modules
| Module | Description |
|---|---|
| api_databases | Connecte des applications Node.js à des bases de données (MongoDB, SQLite, Elasticsearch) via des API REST, avec opérations CRUD et gestion des requêtes. |
| auth_api | Flux d’authentification complets : inscription, connexion, gestion de tokens JWT ou sessions. Fournit des exemples de requêtes cURL pour tester les endpoints. |
| boolean_parser | Analyse et évalue des expressions booléennes depuis des chaînes de caractères (AND, OR, opérateurs de comparaison). Deux variantes : SQL et NoSQL. |
| cluster_example | Clustering Node.js : instanciation de plusieurs processus workers pour exploiter les CPU multi-cœurs via le module cluster natif. |
| data_processing | Suite d’utilitaires de transformation : CSV↔JSON, one-hot encoding, imputation, feature hashing, BPE, matrices creuses, plus-longue sous-séquence commune, etc. |
| data_visualization | Visualisations interactives en HTML : régression linéaire, k-means, DBSCAN, réseau de neurones, arbre de décision, perceptron — rendues dans le navigateur. |
| dataframe | Implémentation d’une structure DataFrame similaire à pandas en JavaScript, avec accès colonnaire, opérations chaînables et support des données tabulaires. |
| deno_server | Serveur REST sous runtime Deno, exploitant le support TypeScript natif et le modèle de permissions orienté sécurité de Deno. |
| etl | Pipeline ETL complet (Extract, Transform, Load) entièrement en JavaScript — extraction de données brutes, transformations et chargement dans un store cible. |
| file_transfer | Upload et download de fichiers en HTTP avec transfert fragmenté et suivi de progression. |
| long_polling | Implémentation du long-polling pour une communication quasi temps-réel sans WebSockets. |
| machine_learning | Algorithmes ML implémentés from scratch : régression linéaire/noyau, perceptron (classique, pocket, multiclasse, large marge), k-means, DBSCAN, arbre de décision, réseau de neurones, autoencoder, k-NN, chaînes de Markov, génération de texte, chatbot multilingue. |
| mock_database | Base de données simulée en mémoire avec parseur booléen intégré — permet de tester la logique applicative sans dépendance externe. |
| scheduler | Planificateur de tâches qui exécute des jobs à intervalles définis, proche d’un cron léger en Node.js. |
| shared_hosting | Configurations et patterns pour déployer des applications Node.js en hébergement mutualisé. |
| signature_api | Génération et vérification de signatures numériques pour webhooks ou documents. |
| tictactoe | Jeu de Morpion avec adversaire IA via recherche minimax dans l’arbre de jeu. |
| timestamp_api | Endpoints de génération, parsing et formatage d’horodatages multi-fuseaux horaires. |
| worker_threads | Parallélisme CPU dans des threads séparés via l’API Worker Threads de Node.js. |
3. Points techniques saillants
3.1 Machine learning sans bibliothèques externes
Le module machine_learning est la partie la plus ambitieuse du dépôt. Chaque algorithme — régression, classification, clustering, réseau de neurones — est implémenté directement en JavaScript sans dépendance externe, ce qui oblige à maîtriser les fondements mathématiques plutôt qu’à déléguer aux abstractions d’une bibliothèque.
Réseau de neurones. L’implémentation de neural_network.js illustre la construction manuelle des structures de poids et de nœuds, la propagation avant et la rétropropagation. Les poids sont organisés en tableaux tridimensionnels (couche × neurone sortant × neurone entrant), et l’initialisation aléatoire est séparée de la phase d’entraînement par un flag Start passé à la fonction GenerateDeepNeuralNetwork().
function GenerateDeepNeuralNetwork(Neurons, Depth, Start) { // Structure de poids : [couche][neurone_out][neurone_in] for (var i = 0; i < Depth + 1; i++) { Weights.push([]) for (var j = 0; j < Neurons; j++) { Weights[i].push([]) // initialisation aléatoire à la construction if (Start !== 1) Weights[i][j].push(Math.random()) } }}


Byte Pair Encoding. Le script byte_pair_encoding.js implémente l’algorithme BPE utilisé dans les tokeniseurs de modèles de langage (GPT, BERT). Le principe : identifier les paires de tokens les plus fréquentes, les fusionner en un seul token, répéter jusqu’à convergence. L’implémentation JavaScript parcourt le tableau en place, remplace les occurrences et maintient un dictionnaire de correspondances pour la reconstruction.
for (var i = 0; i < Str.length; i++) { if (!Pairs.includes([Str[i], Str[i+1]].join('')) && Str[i+1] !== undefined) { Dictionary.push(Value) Pairs.push([Str[i], Str[i+1]].join('')) Str[i] = Value // fusion en place Str.splice(i+1, 1) // suppression de l'élément fusionné Value++ } else if (Pairs.includes([Str[i], Str[i+1]].join('')) ...) { Str[i] = Dictionary[Pairs.indexOf([Str[i], Str[i+1]].join(''))] Str.splice(i+1, 1) }}
3.2 Parseur d’expressions booléennes
Le module boolean_parser analyse des expressions de la forme id=1 OR first=2 AND last=4 et les évalue contre un jeu de données tabulaire. L’implémentation gère la précédence des opérateurs, les parenthèses imbriquées et les opérateurs de comparaison (=, !=, >, <, >=, <=). Deux variantes sont fournies — SQL et NoSQL — ce qui en fait un composant directement réutilisable pour construire un moteur de requêtes dynamiques.
3.3 Parallélisme CPU : deux approches comparées
Les modules worker_threads et cluster_example traitent le même problème — exploiter les CPU multi-cœurs — par deux mécanismes distincts. Le module cluster duplique le processus Node.js entier via fork() (partage du port d’écoute, isolation mémoire complète), tandis que worker_threads crée des threads dans le même processus avec mémoire partagée via SharedArrayBuffer. La coexistence des deux approches dans un même dépôt constitue une comparaison de référence rarement documentée de façon aussi directe.
3.4 Pipeline ETL en JavaScript
Le module etl implémente le pattern canonique du data engineering — Extraire, Transformer, Charger — sans runtime Python ni orchestrateur externe. Cette approche est de plus en plus pertinente à mesure que les stacks de données JavaScript (DuckDB-WASM, Danfo.js, Observable) gagnent du terrain. Node.js peut ainsi servir d’orchestrateur léger pour des flux de données sans introduire un second environnement d’exécution.
3.5 DataFrame from scratch
Construire une abstraction DataFrame en JavaScript (dataframe/) est un exercice exigeant : il requiert une conception soigneuse des structures de données pour l’accès colonnaire, la gestion des types, et des opérations chaînables comparables à pandas. Ce module démontre une compréhension du fonctionnement interne de ces bibliothèques — et non pas seulement de leur API publique.
Partie II
python-projects
Python 100 % · PyMuPDF (fitz) · OpenCV · BeautifulSoup · 16 commits · Licence MIT
1. Vue d’ensemble
Là où le dépôt JavaScript privilégie la largeur — couvrant un grand nombre de domaines techniques —, python-projects privilégie la profondeur dans une niche précise : la manipulation programmatique de documents et d’images. Avec 16 commits et 4 modules, il constitue un effort plus récent et plus ciblé, exploitant les forces de l’écosystème Python pour le traitement de fichiers (PyMuPDF, Pillow, OpenCV) et le scraping web (BeautifulSoup, requests).
Chaque module résout un problème concret : convertir un PDF numérisé en niveaux de gris, découper un livre en chapitres, appliquer un filtre artistique à une photographie, ou extraire des données structurées depuis une page HTML. Cette orientation pragmatique rend le dépôt immédiatement utile au-delà de son intérêt pédagogique.
2. Répertoire des modules
| Module | Description |
|---|---|
| bw_transform_pdf | Applique une transformation en niveaux de gris à chaque page d’un PDF via PyMuPDF + OpenCV. Réduit la taille du fichier et prépare l’impression ou l’archivage. |
| html_parsing_demo | Scraping web éducatif : parsing d’un fichier HTML exporté, extraction de liens et d’URLs d’images, téléchargement local. Utilise BeautifulSoup et requests. |
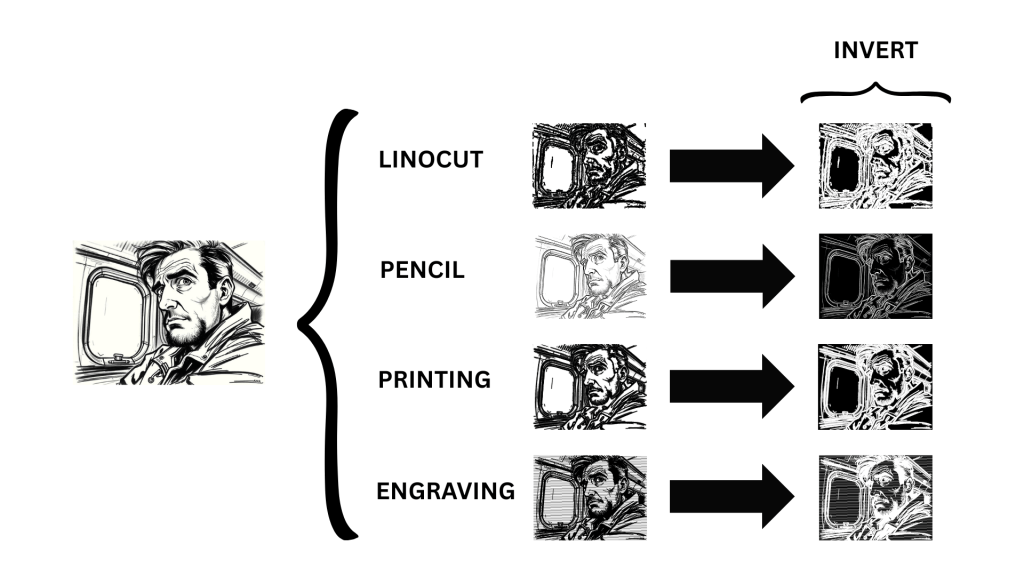
| linocut | Filtre graphique inspiré de la linogravure : quatre styles (linocut, pencil, engraving, printing), paramètres de détail et contraste, traitement en lot via CLI. |
| split_pdf_book | Découpe d’un PDF multi-pages en chapitres individuels. Deux scripts : détection automatique des titres par recherche textuelle (delimit_chapters.py), puis découpe (cut_file.py). |
3. Points techniques saillants
3.1 Conversion PDF en niveaux de gris — bw_transform_pdf
Le script bw_transform_pdf.py combine PyMuPDF et OpenCV pour traiter chaque page d’un PDF. La page est d’abord rastérisée en bitmap haute résolution (facteur 2,5×) via fitz.Matrix(2.5, 2.5), ce qui garantit une qualité suffisante pour la conversion. Le buffer de pixels est ensuite converti en tableau NumPy et traité par OpenCV.
Pipeline page par page :
for page in doc: mat = fitz.Matrix(2.5, 2.5) # rastérisation haute résolution pix = page.get_pixmap(matrix=mat) img = np.frombuffer(pix.samples, dtype=np.uint8) .reshape(pix.h, pix.w, pix.n) if pix.n == 4: # gestion du canal alpha img = cv2.cvtColor(img, cv2.COLOR_BGRA2BGR) bw = bw_editorial(img) # conversion + seuillage ok, buffer = cv2.imencode(".jpg", bw_rgb, [int(cv2.IMWRITE_JPEG_QUALITY), 90]) new_page.insert_image(new_page.rect, stream=buffer.tobytes())
La fonction bw_editorial() applique un flou gaussien (5×5) avant le seuillage adaptatif gaussien avec un bloc de 31 pixels et une constante C de 5. Cette combinaison lisse le bruit de numérisation sans écraser les détails typographiques, ce qui est critique pour les PDFs de texte imprimé.
3.2 Découpe de PDF par chapitres — split_pdf_book
Le module se compose de deux scripts conçus pour fonctionner en séquence. delimit_chapters.py localise les pages de début de chaque chapitre par recherche textuelle ; cut_file.py effectue la découpe physique du PDF.
Détection des titres. La fonction normalize_text() normalise le texte de chaque page avant la comparaison : décomposition Unicode NFKD pour supprimer les diacritiques, remplacement des tirets typographiques, collapse des espaces multiples, conversion en majuscules. La recherche est volontairement restreinte aux 1 200 premiers caractères de chaque page (first_part = text[:1200]), évitant les faux positifs sur les titres cités en corps de texte.
def normalize_text(s): s = unicodedata.normalize("NFKD", s) # décomposition diacritiques s = "".join(c for c in s if not unicodedata.combining(c)) # suppression accents s = s.replace("—", "-").replace("–", "-") s = " ".join(s.split()) # collapse espaces return s.upper()
Découpe. Le script cut_file.py reçoit en entrée la liste des chapitres avec leurs bornes de pages ((titre, page_début, page_fin)) et construit un nouveau document PyMuPDF pour chacun via insert_pdf(). Les noms de fichiers sont des slugs normalisés dérivés des titres, générés par delimit_chapters.py lors de la phase de détection.
3.3 Scraping HTML éducatif — html_parsing_demo
Le script opère sur un fichier HTML exporté localement (plutôt qu’en crawlant directement un site), ce qui constitue une approche respectueuse des conditions d’utilisation des plateformes. Il extrait les liens et URLs d’images via BeautifulSoup, applique un filtre de section configurable (TARGET_SECTIONS), impose un délai entre les requêtes (REQUEST_DELAY = 2 secondes) et plafonne le nombre de téléchargements (MAX_DOWNLOADS). Ces garde-fous illustrent une pratique de scraping responsable.
| Le module linocut — filtre artistique de linogravure — est documenté en détail dans la documentation technique de sketch_filter.py. On s’y reportera pour la description des algorithmes de rendu (linocut, pencil, engraving, printing) et des paramètres de traitement par lot. |
Synthèse comparative
| JavaScript | Python | |
|---|---|---|
| Commits | 484 | 16 |
| Modules | 19 | 4 |
| Philosophie | Largeur — de nombreux domaines couverts | Profondeur — niche document/image |
| Runtime | Node.js + Deno | Python 3 |
| Dépendances clés | Aucune (ML from scratch) | PyMuPDF, OpenCV, BeautifulSoup |
| Visualisation | HTML interactif (navigateur) | — |
| Orientation | Pédagogique & référence | Utilitaire & pragmatique |
Les deux dépôts se complètent sans se chevaucher : le dépôt JavaScript explore la largeur du data engineering et du machine learning dans un écosystème runtime où ces pratiques sont moins conventionnelles, tandis que le dépôt Python tire parti des bibliothèques spécialisées de l’écosystème Python pour résoudre des problèmes de traitement documentaire concrets. L’ensemble témoigne d’une maîtrise des deux langages dans leurs usages respectivement les plus pertinents.

Laisser un commentaire