
Nous allons aborder la question de la compréhension du langage par une machine, en construisant un outil de classification de textes. Le domaine du traitement automatique du langage naturel est très vaste dans la mesure où les applications et ramifications de cette discipline sont très nombreuses. Nous verrons donc brièvement ce qu’est le traitement automatique du langage, puis nous verrons comment convertir du texte en quelque chose d’exploitable par un perceptron, et enfin, nous construirons ce dernier pour classer des phrases.
Table des matières :
- Qu’est-ce que le traitement automatique du langage naturel ou NLP (Natural Language Processing) ?
- Classification
- Construction d’un classifieur
- Rendre un texte exploitable par un perceptron
- Validation et tests avec le classifieur
- Conclusions
Qu’est-ce que le traitement automatique du langage naturel ou NLP (Natural Language Processing) ?
Le traitement automatique du langage naturel ou NLP en anglais (pour Natural Language Processing ) est une science dont l’histoire remonte aux années 1950, et qui consiste à apprendre à une machine à traiter le langage de façon automatique. Les premières applications du NLP étaient souvent militaires, avec des travaux principalement orientés vers la traduction de documents dans le contexte de la Guerre Froide. La discipline s’est ensuite progressivement élargie vers des applications civiles, avec le développement des premiers chatbots comme ELIZA qui devait être capable d’imiter des conversations avec un véritable être humain.
Un autre champ qui a vu se développer ce que l’on appelle les “interpréteurs de commande” — des algorithmes/programmes d’interpréter des demandes écrites par ordinateur — est le domaine du jeu vidéo. Les premiers jeux étaient des fictions interactives avec seulement du texte et une interface pour saisir des instructions (“tourner à droite”, “prendre le journal sur la table”, “ouvrir la porte”….). L’exemple iconique est la série de jeux vidéos “ZORK” développés par INFOCOM à la fin des années 1970 puis début des années 1980.
La discipline du traitement automatique du langage naturel doit être vue comme un champ multidisciplinaire qui regroupe l’informatique, la linguistique, parfois de la psychologie ou encore l’intelligence artificielle. Par conséquent, le développement d’applications à l’aide du NLP implique très souvent des connaissances dans plusieurs autres domaines, et notamment dans le domaine de la linguistique. Ces applications sont nombreuses comme la traduction automatique, la reconnaissance vocale, la conversion de la parole en texte ou encore les agents conversationnels (ou chatbots). Dans cet article, nous allons nous concentrer sur la création d’un outil de classification de phrases, à l’aide d’un perceptron — un algorithme ancien de machine learning. En voici deux schémas — la forme “simple” et la forme dite “multi-couche” :
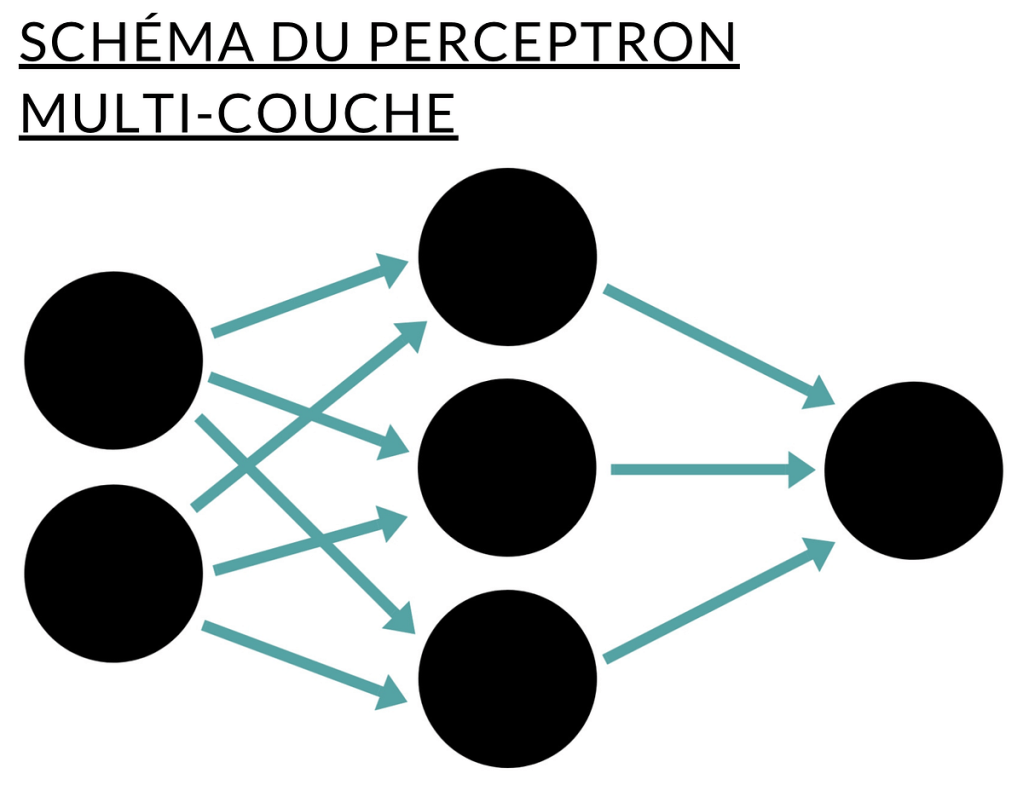
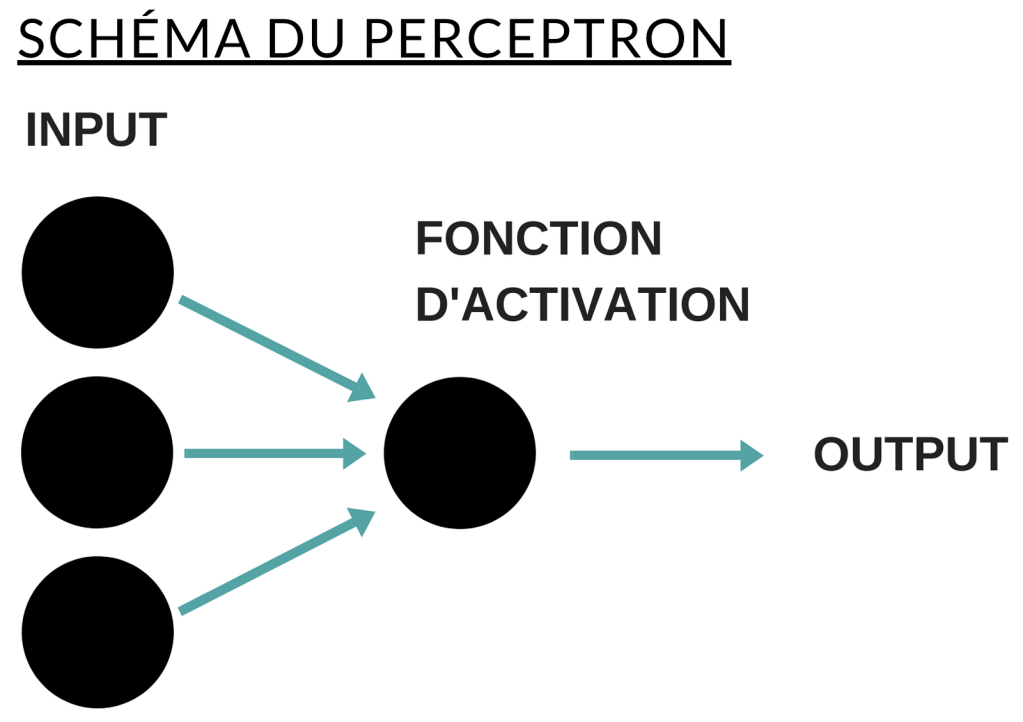
Le système est simple : on injecte des données en entrée, une fonction d’activation estime une “classe” d’appartenance puis le résultat est communiqué sous forme de probabilité. Le perceptron “simple” ne peut classer que des données linéairement séparables — pour faire simple, une droite ou un plan dans un espace de représentation donné. Le perceptron “multi-couche” — avec plusieurs couches de neurones artificiels — peut quant à lui traiter des données non-linéaires — séparables avec une courbe par exemple.
Classification
La classification de phrases est une tâche simple qui consiste à prendre des phrases pour en déterminer le sujet général. Cela est par exemple très utile lorsque nous avons besoin de réaliser un travail de pré-qualification de l’information : est-ce que le texte parle de météo ? Est-ce qu’il s’agit d’une rubrique sportive ? Il s’agit d’un travail couramment effectué par exemple par des chatbots. En effet, avant même de vouloir extraire de l’information, il est d’abord nécessaire de comprendre d’abord l’intention générale du locuteur. Comme ces informations sont souvent complexes, parfois ambivalentes et peu standardisées, il est souvent assez inefficace de vouloir coder des règles précises dans le but de déterminer si cette phrase parle de météo ou s’il s’agit d’une brève d’actualité. C’est la raison pour laquelle les algorithmes de machine learning (qui s’appuient non pas sur des règles explicites mais sur des exemples et contre-exemples) sont de plus en plus utilisés pour réaliser des opérations de traitement du langage naturel, car on cherche avant tout à repérer des schémas généraux.
Construction d’un classifieur
La mise en place d’un outil de classification de textes peut se faire très simplement de la façon suivante :
- Choisir des phrases d’entraînement et déterminer des classes d’appartenance pour chacune d’entre elles
- Déterminer les mots uniques dans l’ensemble de ces phrases pour construire nos inputs
- Apprendre à notre perceptron à différencier ces phrases
- Puis valider le bon entraînement de notre perceptron
Le but ici est d’apprendre les quelques bases essentielles du traitement automatique du langage naturel du traitement des inputs jusqu’à l’obtention des résultats finaux, et de comprendre comment s’organise une telle démarche. Nous ne rentrerons donc pas dans l’ensemble des subtilités liées au traitement automatique du langage naturel.
Rendre un texte exploitable par un perceptron
Avant même de construire un algorithme, nous devons d’abord convenir d’une méthode pour transformer les phrases en des signaux exploitables par un algorithme. Les mots d’une ou plusieurs phrases ne sont pas directement exploitables en l’état par un perceptron, un réseau de neurones multicouches ou tout autre algorithme, dans la mesure où ces algorithmes ne travaillent pas avec des lettres mais avec des valeurs numériques. Prenons par exemple les quatre phrases suivantes :
- See you later
- Have a nice day
- Talk to you soon
- Give me a salad
- Do you have hamburgers
- Can I have a sandwich
Nous avons donc trois phrases pour dire au revoir et trois phrases pour demander à manger. Ce qui veut dire que nous allons avoir deux classes :
- Un output de 1 pour une phrase d’au revoir
- Un output de 0 pour demander à manger
Pour pouvoir exploiter nos phrases et entraîner un perceptron, nous devons convertir ces phrases en inputs. Ce travail se fait grâce à une méthode d’encodage qui consiste à repérer d’abord l’ensemble des termes uniques, puis à signaler la présence par une valeur de 1 si le mot est présent, ou 0 s’il est absent. Nous allons donc d’abord consigner chacun des termes uniques présents dans les phrases précédentes, soit :
'see', 'you', 'later', 'have', 'a', 'nice', 'day', 'talk', 'to', 'soon', 'give', 'me', 'salad', 'do', 'hamburgers', 'can', 'i', 'sandwich'
Ce qui va nous permettre de convertir nos phrases en des inputs, en convertissant chaque mot en un signal binaire sous la forme de 0 et de 1. Nous obtenons au final la matrice suivante :
see you later 1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
have a nice day 0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0
talk to you soon 0,1,0,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0
give me a salad 0,0,0,0,1,0,0,0,0,0,1,1,1,0,0,0,0,0
do you have hamburgers 0,1,0,1,0,0,0,0,0,0,0,0,0,1,1,0,0,0
can i have a sandwich 0,0,0,1,1,0,0,0,0,0,0,0,0,0,0,1,1,1
Voici également un exemple de code pour le réaliser automatique :
var Input = [ 'see you later', 'have a nice day', 'talk to you soon', 'give me a salad', 'do you have hamburgers', 'can i have a sandwich']
for (var i = 0; i < Input.length; i++) {
Input[i] = Input[i].split(' ')
}
var UniqueWords = []
for (var i = 0; i < Input.length; i++) {
UniqueWords.push(…new Set(Input[i]))
UniqueWords = […new Set(UniqueWords)]
}
var Output = []
for (var i = 0; i < Input.length; i++) {
Output.push([])
}
for (var i = 0; i < Input.length; i++) {
var Word = Input[i]
for (var j = 0; j < UniqueWords.length; j++) {
for (var k = 0; k < Word.length; k++) {
if (Word[k] === UniqueWords[j]) {
Output[i].push(1)
break
} else if (k === Word.length - 1) {
Output[i].push(0)
}
}
}
console.log('\n' + Word.join(' ')) console.log(Output[i].toString())
}
Et voici un exemple de résultat :
see you later 1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
have a nice day 0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0
talk to you soon 0,1,0,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0
give me a salad 0,0,0,0,1,0,0,0,0,0,1,1,1,0,0,0,0,0
do you have hamburgers 0,1,0,1,0,0,0,0,0,0,0,0,0,1,1,0,0,0
can i have a sandwich 0,0,0,1,1,0,0,0,0,0,0,0,0,0,0,1,1,1
Maintenant que cela est fait, nous allons pouvoir passer à la seconde étape qui consiste à organiser le traitement de ces informations à l’aide d’un perceptron. Création du classifieur de textes Maintenant que nous savons comment convertir des phrases en un signal “audible” par un perceptron, nous allons mettre en place ce dernier pour apprendre à classifier des phrases. Comme vous allez le voir, il n’est pas forcément nécessaire de mettre en place des algorithmes complexes pour réaliser des opérations simples comme de la classification de textes.
Pour commencer, nous allons d’abord déclarer les mots uniques stockés “UniqueWords”, les inputs dans une variable “Input”, les outputs dans une variable “Output”, ainsi que les autres variables nécessaires au fonctionnement du perceptron. Nous allons également ici initialiser les valeurs des poids :
var UniqueWords = ['see', 'you', 'later', 'have', 'a', 'nice', 'day', 'talk', 'to', 'soon', 'give', 'me', 'salad', 'do', 'hamburgers', 'can', 'i', 'sandwich']
var Input = [
[1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0],
[0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0],
[0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]]
var Output = [1, 1, 1, 0, 0, 0]
var Weights = []
var InitialSum
var FinalSum
for (var i = 0; i < Input[0].length; i++) {
Weights.push(Math.random())
}
Nous allons ensuite créer une fonction perceptron, et créer une boucle pour l’entraîner :
function Perceptron (Input, Output) {
InitialSum = 0
for (var a = 0; a < Input.length; a++) {
InitialSum = InitialSum + (Input[a] * Weights[a])
}
if ( InitialSum > 0) {
FinalSum = 1
} else {
FinalSum = 0
}
var TargetCalculated = Output - FinalSum
for (var b = 0; b < Input.length; b++) {
Weights[b] = Weights[b] + TargetCalculated * Input[b] * 0.001
}
InitialSum = 0
for (var c = 0; c < Input.length; c++) {
InitialSum = InitialSum + (Input[c] * Weights[c])
}
if ( InitialSum > 0) {
FinalSum = 1
} else {
FinalSum = 0
}
}
for (var a = 0; a < 500; a++) {
for (var b = 0; b < Input.length; b++) {
Perceptron(Input[b], Output[b])
}
}
Comme vous pouvez le constater, l’organisation générale de notre algorithme reste inchangée. Nous allons maintenant pouvoir passer à la troisième étape qui consiste à valider l’entraînement et classer de nouvelles données, et où nous allons également voir plus en détail comment organiser le traitement de nouveaux inputs sous forme de phrases non préparées.
Validation et tests avec le classifieur
Maintenant que nous avons programmé notre perceptron, nous allons pouvoir l’utiliser pour classer des phrases qui ne sont pas préparées. Le code qui va suivre est très similaire à celui en introduction pour réaliser la préparation des données. Créons juste à la suite une variable “Sentences”, qui va contenir différentes phrases que nous souhaitons confronter à notre perceptron (en l’occurrence, nous souhaitons ici valider le bon entraînement de ce dernier, mais nous ajoutons également quelques phrases nouvelles) :
var Sentences = ['see you later', 'have a nice day', 'see you soon', 'talk to you soon', 'give me a salad', 'do you have hamburgers', 'can i have a sandwich', 'i want a coffee']
Nous démarrons ensuite une boucle à travers chacune des phrases enregistrées dans la variable. Ajoutez le code suivant :
for (var i = 0; i < Sentences.length; i++) {
Nous mettons à zéro la valeur de la variable “Input”, et nous utilisons la fonction split pour découper les phrases contenues dans la variable “Sentences” en plusieurs mots distincts, que nous stockons ensuite dans une variable “Words” :
Input = []
var Words = Sentences[i].split(' ')
Nous allons ensuite chercher à savoir si les mots de cette phrase correspondent à des termes uniques que nous avons enregistrés plus haut dans notre programme dans une variable nommée “UniqueWords”. Nous mettons en place la méthode suivante :
- Nous commençons d’abord par récupérer un terme unique au sein de la variable “UniqueWords” à l’aide d’une première boucle
- Nous cherchons ensuite dans la phrase précédemment découpée en mots distincts, s’il existe une concordance, à l’aide d’une seconde boucle.
Celle-ci fonctionne jusqu’à atteindre les limites de la variable “Words”. Si c’est le cas, la boucle s’arrête, et nous passons une valeur de 1 en input. Dans le cas contraire, nous enregistrons une valeur d’input égale à 0. Ce travail se poursuit jusqu’à atteindre la limite de la variable “UniqueWords”.
for (var a = 0; a < UniqueWords.length; a++) {
for (var b = 0; b < Words.length; b++) {
if (Words[b] === UniqueWords[a]) {
Input.push(1) break
} else if (b === Words.length - 1) {
Input.push(0)
}
}
}
Une fois que nous avons pu calculer la valeur de l’input, nous pouvons l’utiliser en faisant une propagation vers l’avant avec notre perceptron. Il suffit d’utiliser la matrice des poids obtenue après entraînement avec les précédentes données contenues dans la variable “Input”. C’est la raison pour laquelle nous pouvons librement réutiliser cette variable, comme nous avons uniquement besoin des poids pour réaliser des prédictions. Nous ajoutons alors le code suivant, et nous imprimons les résultats dans la console :
InitialSum = 0
for (var c = 0; c < Input.length; c++) {
InitialSum=InitialSum + (Input[c] * Weights[c])
}
if (InitialSum > 0) {
FinalSum = 1
}
else {
FinalSum = 0
}
console.log('Sentence : '+Sentences[i])
console.log('Input : ['+Input+']') console.log('{ Result : '+FinalSum+' }')
}
Voici un exemple de résultats que vous pouvez obtenir (je précise qu’il peut y avoir quelques variations du fait du manque de finesse du perceptron, et de la très faible taille du jeu de données pour l’apprentissage, et aussi parce que nous utilisons uniquement la dernière solution trouvée par le perceptron) :
see you later => [1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] { Result : 1 }
have a nice day => [0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0] { Result : 1 }
see you soon => [1,1,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0] { Result : 1 }
talk to you soon => [0,1,0,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0] { Result : 1 }
give me a salad => [0,0,0,0,1,0,0,0,0,0,1,1,1,0,0,0,0,0] { Result : 0 }
do you have hamburgers => [0,1,0,1,0,0,0,0,0,0,0,0,0,1,1,0,0,0] { Result : 0 }
can i have a sandwich => [0,0,0,1,1,0,0,0,0,0,0,0,0,0,0,1,1,1] { Result : 0 }
i want a coffee => [0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,1,0] { Result : 0 }
En dépit du faible nombre de phrases d’entraînement, notre perceptron est apte à proposer une classification assez correcte des différentes phrases. Toutefois, le faible nombre de phrases d’entraînement, et les contraintes liées à l’usage d’un perceptron, limitent les capacités de notre outil de classification. L’inconvénient majeur du perceptron binaire tient au fait qu’il ne peut classer des données qu’en deux classes distinctes, ce qui ne permet pas de percevoir une quelconque nuance dans le sens d’une phrase. Dans la réalité, on cherche plus souvent à obtenir un score d’appartenance à une classe pour ensuite prendre une décision de classement.
Conclusions
Nous avons donc appris à convertir des phrases en un signal “audible” pour une machine, à créer un outil de classification de textes et à classer des phrases. Comme vous pouvez le constater, il n’est pas impossible de construire un tel outil avec un algorithme aussi simple que le perceptron. Pour aller plus loin, vous pourriez par exemple tenter d’accroître le nombre de phrases d’entraînement, ou encore développer un outil de classification à l’aide d’un réseau de neurones multicouches . Un autre travail intéressant peut consister à réaliser ce même travail dans différentes langues.

Laisser un commentaire